如何分析与解决Google 中的“已抓取– 尚未编入索引”
Contents
“已抓取 – 尚未编入索引”是Google Search Console网站索引报告中常见的一项。根据谷歌的官方文档,这个状态的意思是:“Google 已抓取相应网页,但尚未将其编入索引。日后,该网页可能会被编入索引,也可能不会被编入索引;无论如何,您都无需重新提交该网址以供抓取。”
从Google的这个定义中,我们知道3个事实:
- Google 能够访问该页面
- Google 花了一些时间来抓取该页面
- 爬取后,Google决定不收录
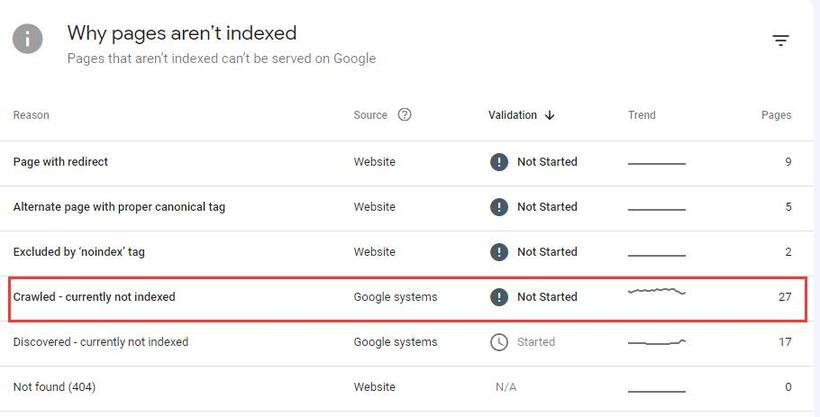
Google没有给出一个明确的答案,为什么给定的页面被抓取但没有被编入索引。但是,为了解决这个问题,我们需要了解Google为什么有意识地决定不收录这些页面。
在下文中,我列出了可能导致页面“已抓取 – 当前未编入索引”的常见问题以及使 Google 将其编入索引的可能解决方案。
如何修复 Google Search Console 中的“已抓取 – 当前未编入索引”错误
原因1:数据误报
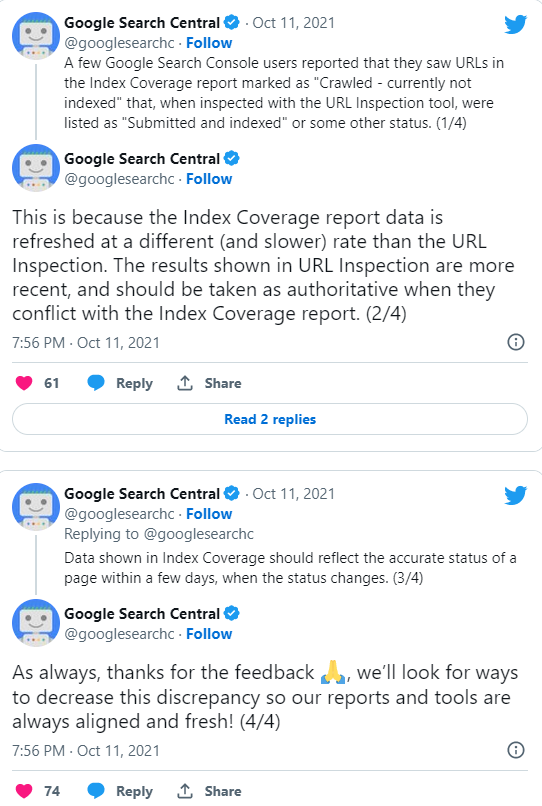
当您注意到一个 URL 被标记为“已抓取– 尚未编入索引”时,您可以使用 URL 检查工具检查该页面。如果 URL 检查工具将页面标记为已编入索引,则表明Google Search Console 中的报告之间存在差异。此外,你还可以通过site的高级搜索指令查看对应页面是否已被Google收录。
谷歌曾解释说,与他们的 URL 检查工具相比,页面索引报告数据的刷新速度通常速度较慢。因此,页面索引报告通常需要几天时间才能反映页面的实际状态。
优先级:低
解决方案:无需解决
原因2:RSS feed URLs
这也是常见的例子之一。如果您的站点使用 RSS Feed,你可能会发现部分含有“/feed/”字符串的URL出现在Google 的“已抓取 —尚未编入索引”报告中。例如:
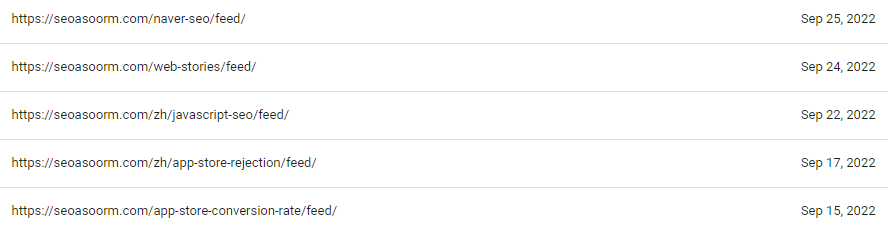
RSS Feed有助于内容分发,但这些URL不适合人类阅读,因为它们没有格式。因此,Google可能有选择地不收录这些URL, 因为这些内容本身不是为用户准备的。
优先级:低
解决方案:无需解决
原因3:内容分页
“已抓取 – 当前未编入索引”另一个极其常见的原因是分页。分页 URL 是在末尾带有代表页面的数字的页面 – 例如,www.mydomain.com/blog/page/2。
我们经常会看到大量分页 URL 出现在该报告中:

Google 需要抓取分页 URL 才能完整抓取网站。这是它通往内容的途径。然而,虽然谷歌使用分页作为访问内容的途径,但它不一定需要索引分页URL。
优先级:低
解决方案:无需解决
原因4:内容薄弱及质量低
有时我们会看到此报告中包含的 URL 内容非常少或只是堆积了低质量的文字。这些页面可能已正确设置所有技术元素,甚至可能有正确的内部链接,但是,当 Google 遇到这些 URL 时,页面上的实际内容很少或质量低下以至于Google认为它们没有用。
如果你注意到在“已抓取 – 当前未编入索引”中列出的大多数都是内容分页,RSS Feed以及其他内容非常稀少的杂项页面,那么你可以理解为这些页面没有为用户提供任何价值以提供Google索引它们的动力。如果是这些情况,你可以忽略。
但是,如果您看到您网站上的很多重要页面(有价值/有用的信息)被列在此处,这可能是整个站点范围内的质量问题影响了您的重要页面被编入索引。
优先级:高
解决方案:
作为网站所有者,您应该确保您的页面提供高质量的内容。检查它是否可能满足用户的意图,并在需要时添加高质量的内容。Google提出来一系列问题来帮助您确定内容的价值:
- 内容是否提供了原创的信息、报告、研究或分析?
- 内容是否提供了对主题的实质性、完整性或全面性描述?
- 内容是否提供了富有洞察力的深刻见解或有趣信息?
- 如果内容借鉴了其他来源,它是否避免了简单地复制或改写那些来源,而是提供了实质性的额外价值和原创性内容?
- 标题和/或网页标题是否对内容进行了非常实用的描述性总结?
- 标题和/或网页标题是否避免了夸大其词或耸人听闻?
- 您会将这种网页添加为书签、分享给朋友或推荐给他人吗?
- 您觉得这样的内容会出现在印制的杂志、百科全书或书籍中或被它们引用吗?

另一个需要关注的方面是优化网站上用户生成的内容。例如,假设您有一个论坛,有人问了一个问题。尽管将来可能会有很多有价值的回复,但在抓取时没有回复,因此 Google 可能会将页面归类为低质量内容。
此外,您可以通过系统地从索引中删除低质量页面来提高整体站点质量。但是,网站质量并不是一夜之间就能改变的。谷歌需要一段时间来接收信号、重新处理和重新评估您的整体网站质量。
原因5:重复内容
如果 Google 认为您的内容重复,它可能会抓取该内容但选择不将其包含在索引中。这是 Google 避免 SERP 重复的方法之一。通过从索引中删除重复内容,Google 确保用户可以在搜索结果中看到更多内容独特的页面。
有时报告会将这些 URL 标记为“重复”状态【重复网页(Google 选择的规范网页与用户指定的不同)】,有时则不会。
优先级:高
解决方案:如果您注意到索引报告中有很多重复内容,请评估以下元素:
- 规范标签(Canonical Tag):这些 HTML 标签告诉搜索引擎哪些版本是原始版本。
- 内部链接:确保内部链接指向您的原始内容。Google 可能会使用它作为哪个页面更重要的指标。
- XML 站点地图:确保站点地图中只有规范版本。
更为重要的是,你可能需要在高优先级的页面上重新内容或提供更多独特内容,而不是大量适用模板化的文案,以增强页面内容的独特性。
原因6:糟糕的内链结构
良好的网站架构是帮助您最大限度地提高索引机会的关键。它帮助Google发现您的内容并更好地理解页面之间的关系。
这就是为什么提供良好的网站架构并确保你希望被索引的页面有指向其的内链的至关重要的原因。
让我们想象一下这样一种情况,您有一个质量很好的页面,但 Google 找到它的唯一方法是因为您将它放在您的站点地图中。
Google 可能会查看该页面并抓取它,但由于没有内部链接,它会认为该页面的价值低于其他页面。没有语义或结构信息来帮助它评估页面。这可能是 Google 决定专注于其他页面并在抓取该页面后将其排除在索引之外的原因之一。
优先级:高
解决方案:向 Google 表明您的内容很重要的一种快速方法是从重要页面链接到它。具体来说,你应该设计合理的网站结构使站内的“内链”自然流动与形成、排除孤岛页面。
“已抓取– 尚未编入索引” vs. “已发现– 尚未编入索引”
很多人通常将“已抓取– 尚未编入索引”的状态与Google Search Console索引报告中的另一个问题 “已发现– 尚未编入索引”混淆。
这两种状态都表示该页面未编入索引(未被收录)。但是,在“已抓取 – 当前未编入索引”的情况下,Google 已经访问过该页面。然而,在“已发现 – 当前未编入索引”中,该 URL 为 Google 所知,但由于某种原因尚未被抓取。
| 已抓取– 尚未编入索引 | 已发现– 尚未编入索引 | |
| Google已发现的页面 | 是 | 是 |
| Google访问过的页面 | 是 | 否 |
| 页面收录 | 否 | 否 |
这些状态的某些原因可能是相似的,包括页面质量差和内部链接问题。但是,当您看到“已发现 – 当前未编入索引”的状态时,您需要另外调查为什么 Google 不能或不想访问该页面。例如,它可能表示网站的整体质量存在问题、抓取预算问题或服务器过载。具体可查看我们关于如何解决“已发现 – 当前未编入索引”的文章。
结语
造成“已抓取– 尚未编入索引”的原因可能有很多,但排除数据错误、内容分页、RSS Feed等无需我们修复的原因,我认为最主要的原本在于网站内容质量差或内容重复。
若你发现网站中很多你认为的重要页面被列入“已抓取– 尚未编入索引”,你最应该做的可能是加强内容、或索性主动叫 Google 不用收录这些页面。
